Human Element Digital Marketing Strategists Michelle Abbey and Jordan McKinley also contributed to this post.
The Human Element Digital Marketing team sat down last week to review findings from the Google search API leak now that the SEO community has had a chance to really ingest the 2500+ pages of documents. Here’s how we’re thinking about shifting strategies for eCommerce and lead generation businesses based on what we know today.
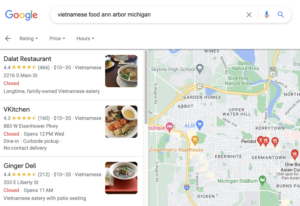
Local Clicks > Distributed Traffic?
The effect that location has on search results has gotten much more complicated. It looks like there’s this tight connection between the location of users clicking (i.e., where they are in the world) and results for the pages they click on.
The overall metric is called NavBoost – everything related to user clicks and page engagement feeds that metric. Part of that is a localized click-through rate.
The API jargon reads:

It’s apparently a replacement for a deprecated geolocation system called “docloc.”
The main implication of the documentation is that there’s likely a multiplier-based score for how far the user was from the address associated with a website when they clicked on a search results link. The closer they were, the greater weight given to that engagement.
Does this mean that users in regions that engage with a website often are affecting search results more?
While that could also be happening, this API works in the inverse; it’s not about where the site’s largest audience is located that determines the weight, but whether the users are close to the business – even if that business is a national retailer that doesn’t focus on a local audience.
Many of our clients fall into this category; EOTECH would be one of them. They have a physical headquarters on their site in their contact section with appropriate markup. Clicks from near that physical HQ may have more importance for them than clicks from other locations.
This idea needs to be proven, but it could help to set up VPNs that are associated with a local area connected to our clients. If that helps some of our development, testing, validation, and analysis count toward site engagement, it’s an easy boost.
Is this factor a boost for local businesses? Or punishment for SEO agencies?
In one sense, it’s like they’re giving brick-and-mortar businesses a little leg-up over eCommerce sites. Of course, that’s an issue for retailers that are online only, where their competition is mostly big box stores. Those stores are getting lots of local clicks that don’t really connect to being an important part of the community.
The more cynical way to take it is as a knock against agencies, because a business that works on its own website will have significant traffic originating from that business and the nearby area. That is not the case for most agencies. This factor could be a simple way to make all of that SEO just a little bit worse.
One agency takeaway may be to select the city for your client on your VPN when working for them. Another tactic that we’re seeing is developing localized content bundles as SEO bait for local searchers. If that can outrank other sites in the area, those clicks are really valuable.
Title Tags are a Ranking Factor After All
How many statements have we read from Google saying “we don’t look at title tags”? They ring hollow now that the ranking factor for title tags is out there for us to see.
The implementation is complicated; our best guess is that first, this feature analyzes page titles against the queries that generated page visits to generate a score for that page. Then, those scores are aggregated for the entire site to create a sitewide title match score that’s actually used for rankings.
For example: Website A has 5 pages, each with a great title match to user queries: it should have a good title match score. Now you put up another page with a poorly matched title tag. That new page is still getting the boost from the sitewide title match score the same as the rest of the pages. That score will dip once it gets recalculated, and then all of the pages on the site will have that new, lower title match score.
It’s like it’s buffered against adding individual pages or a title tag changing on one page or another. It’s also a huge bias towards very large sites. For eCommerce clients in particular, it will be even more important to target long-tail keywords in title tags, both to compete with other sites and to develop a good title match score. Generic keyword targeting is not going to get as good a score in most cases.
What did we know about title tags before this leak?
It’s worth stating that this use of titles is a direct contradiction to years of webmaster guidelines. Sure, it’s more complicated than “good title tag = good ranking,” but they totally make a difference. It’s possible this kind of metric exists for other site parameters like headings, but we haven’t seen that so far.
Quality Rater Scores as Algorithm Input
The Google Search Quality Rater program is where real people, working as contractors for Google, provide ratings and feedback on search results. The program has been around for a long time, but how it’s used has always been unclear. Google’s line has been that those scores are used to evaluate the quality of Google’s algorithm for internal research.
It makes sense; if you’re Google and you see searches with low quality scores for the results given, that’s potentially an algorithm problem. Maybe tweaking something related to that industry or keyword sector or something bigger will get the scores up.

That’s been the official story, and it’s not necessarily untrue… but now we know that the feedback from quality raters is used in the Search API. It strongly suggests that sites that are reviewed by quality raters have those ratings as a direct input for rankings.
Cyrus Shepard, the owner of Zyppy SEO, has been in this since 2009. He managed to get hired as a quality rater (quite the background check failure on Google’s part), and he went through how he was asked to rate websites.
In short, there’s a lot: website reputation, author reputation, ‘YMYL’ status (if the site is about ‘your money or your life’), and subjective content quality all show up in the ratings. The ‘needs met’ score is interesting, and there’s a user intent score for SERPs that might be setting whether a keyword is for purchase, research, updates, or something else. Ad placements might be based on that input, but we don’t know for sure.
The guidelines aren’t enough to tell an SEO how to do their job, but playing to them directly could be more beneficial than previously thought. We don’t know which websites are being visited by search raters regularly, but if they’re YMYL, in a restricted industry, or are just highly visited, it’s more likely. Our clients in the international medical industry could own some of those websites.
What are the signs of Search Raters affecting the results?
The thing we’d look for is results on the page that are (1) on sites meeting those high scrutiny criteria, and (2) results in an order that betrays other similar searches. We’re sure Amazon gets visited constantly by search raters, even to the degree that there may be individual products with extensive search rating scores. It could explain the difference between the searches where a niche retailer has a shot against Amazon and other huge retailers and where they don’t.
Mentions Replacing Links? Maybe!

There’s mounting evidence to suggest that mentions may have replaced links as the primary authority indicator in the algorithm. Mentions encompasses lots of content types: social media, news, blogs, stores, directories – the list goes on. What we might be seeing is the remaking of ranking factors that were once based around links but were exploited by the SEO industry to irrelevance.
What does “remaking ranking factors” mean?
When I (Dane Dickerson, Team Lead) was an SEO intern in 2013, most of my job was adding clients into local business directories. We only submitted to directories that provided a link because at that time, directory links helped quite a bit for local SEO, though it was on its way out.
That was totally exploited and had three big consequences: First, Google stopped giving credit to those links. Second, good SEO agencies stopped providing that service. And third, most directory websites stopped handing out links unless they were no-follow.
If I’m Google looking at the web a few years after killing the ranking factor for local directories, quietly turning on mentions from web directories as a ranking factor could get back the effect that the algorithm originally was after, without tipping off the SEO community to an exploitable factor.
This may be the way that link authority works in most areas. Instead of an actual link, it’s based on a brand name, or author name, or product name, or anything else included in the knowledge graph of a site that is being talked about online, no link required. Structured data is likely a part of building that map.
It may also mean there’s value for websites that sell direct-to-consumer to being listed on a third party seller site, even if it’s not a competitive presence. If selling on Amazon (for a higher price than anywhere else) qualifies as a mention it could boost rankings, even if few people purchase there.
Now that this is out there, we’re sure we’ll see the spammier versions of this get tested in the wild. Should you create clone sites with AI generated content talking about your brand? We don’t know, but there are likely better options that are better for users.
Could mentions also be used as a negative ranking factor? Could a mention from a “toxic” website drag down rankings?

We’re not sure yet, but it could. The Penguin algorithm update in 2012 (the one that tanked link farms) used a binary score for ‘bad’ backlinks. Worth noting that Google insisted at the time that it wasn’t a binary score, but thanks to this leak we know that it was. There’s parts of this leak suggesting that links from low quality sites are just ignored, but we don’t know yet.
Another implication that Rand Fishkin points out in his coverage is that if you’re hiring a blog writer, or publishing blog content from multiple people, it’s likely better to consolidate your articles under a single author with a history of web content than to use multiple voices. C-Suite employees are a go-to choice, but the negative PR possibilities if they get caught off-guard by questions about the content are pretty dangerous. Unfavorable mentions aren’t great, usually.
Site Type Limitations
Site type limitations (a ‘Constraint Method Twiddler’) is a system described where a search engine results page can be regulated with a limit or quota for different types of results. How many should be a wiki type source? How many can be eCommerce sites? How many can be blogs? How many can be video sharing platforms?
What opportunities can site type limitations create for eCommerce websites?
Many of our clients are eCommerce or lead generation oriented sites with blog sections. For a given keyword, if most of the results on the page are eCommerce product pages, it might be a better ranking strategy to write a blog that’s essentially a product feature and optimize it instead of a PDP.
Another idea is to identify search results with blogs that rank oddly high given their metrics, and target them for a blog page; Hopefully, the analytics tools start to pick up on how this might be used and how to find opportunities based on content type.
New Tactics for B2B Clients
For B2B businesses, the biggest thing we’re recommending is to stay well-optimized for long-tail search results; that’s already been a big avenue for business discovery (most businesses are price-conscious shoppers with specific needs), and now there’s good evidence that those interactions lift the site through multiple factors.
The darker implication is that click manipulation may be the best way to boost visibility quickly for many websites. Some APIs refer to multiple link indexes based on quality via clicks and engagements; small manipulations to those pages could be the difference between page discovery today vs. in three months for new websites.
Other agencies and outlets have drawn their own conclusions; Search Engine Land’s Andrew Ansley has written that removing content with low engagement could help with search rater scores and content engagement. We’re skeptical (especially me) – ‘content pruning’ has made the rounds as a trend many times, and I’ve never seen it lift a site up. Moreover, if so much is based on Chrome user data, generating a few clicks to a low engagement page in whatever way available feels far less risky than deleting content currently indexed.
We plan to keep writing about this topic as more tests are run and as Google responds with algorithm changes to counter new strategies. Keep watching this blog for more about this leak, SEO strategy and eCommerce development.
***
Take a look at the first blog post in this series.[/fusion_text][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container]